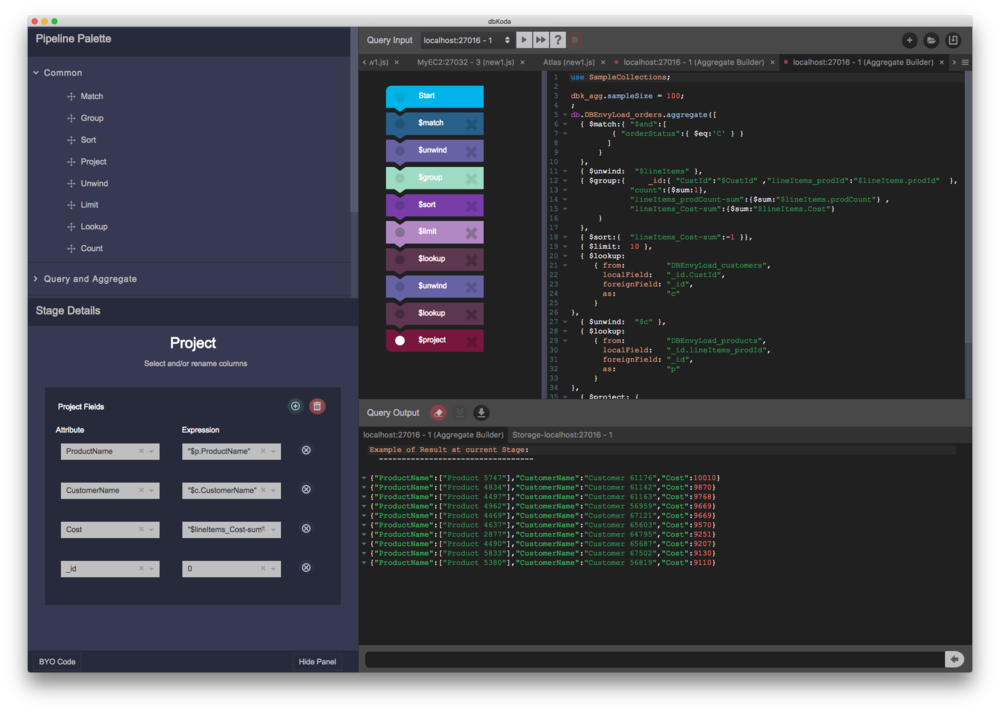
I’ve been looking for an excuse to muck about with scala for a while now. So I thought i’d do a post similar to those I’ve done the past for .NET, python, perl and R. Best practices for Java were included in my book Oracle Performance Survival Guide (but I’d be more than happy to post them if anyone asks).
One of the great things about scala is that it runs in the JVM, so we can use the Oracle JDBC drivers to access Oracle. These drivers are very mature and support all the best programming practices.
Best practices for programming Oracle in any language require at least the following:
- Use bind variables appropriately.
- Ensure you are performing array fetch when retrieving more than one row
- Ensure that you use array insert when doing bulk inserts
You can get the scala program which contains the code snippets below here.
Connecting
If you’ve ever used Oracle with JDBC, you’ll find things very familiar. Here’s a snippet that connects to an oracle database with username,password, host and service specified on the command line (assumes the default 1521 port, but of course this could be parameterized as well):
1: import java.sql.Connection
2: import java.sql.ResultSet
3:
4: import oracle.jdbc.pool.OracleDataSource
5:
6: object guyscala2 {
7: def main(args: Array[String]) {
8: if (args.length != 4) {
9: println("Arguments username password hostname serviceName")
10: System.exit(1)
11: }
12:
13: val ods = new OracleDataSource()
14: ods.setUser(args(0))
15: ods.setPassword(args(1))
16: ods.setURL("jdbc:oracle:thin:@" + args(2)+":1521/"+args(3))
17: val con = ods.getConnection()
18: println("Connected")
Using Bind variables
As in most languages, it's all to easy to omit bind variables in scala. Here's an example where the variable value is simply concatenated into a SQL string
1: for (cust_id <- 1 to rows) {
2: val s1 = con.createStatement()
3: s1.execute("UPDATE customers SET cust_valid = 'Y'"
4: + " WHERE cust_id = " + cust_id)
5:
6: s1.close()
7: }
On line 3 we build up a SQL statement concatenating the value we want into the string and immediately exeucte it. Each execution is a unique SQL statement which requires parsing, optimization and caching in the shared pool.
Here’s an example using bind variables and a prepared Statement:
1: val s2 = con.prepareStatement(
2: "UPDATE customers SET cust_valid = 'Y'"
3: + " WHERE cust_id = :custId")
4:
5: for (cust_id <- 1 to rows) {
6: s2.setInt(1, cust_id)
7: s2.execute()
8: }
9:
10: s2.close()
Slightly more complex: we prepare a statement on line 1, associate the bind variable on line 6, then execute on line 7. It might get tedious if there are a lot of bind variables, but still definitely worthwhile. Below we see the difference in execution time when using bind variables compared with concanating the variables into a string. Bind variables definitely increase execution time.

As well as the reduction in execution time for the individual application, using bind variables reduces the chance of latch and/or mutex contention for SQL statements in the shared pool – where Oracle caches SQL statements to avoid re-parsing. If many sessions are concurrently trying to add new SQL statements to the shared pool, then some may have to wait on the library cache mutex. Historically, this sort of contention has been one of the most common causes of poor application scalability – applications which did not use bind variables risked strangling on library cache latch or mutex as the SQL exectuion rate increased.
Exploiting the array interface
Oracle can retrieve rows either from the database one at a time, or can retrieve rows in “batches” sometimes called “arrays”. Array fetch refers to the mechanism by which Oracle can retrieve multiple rows in a single fetch operation. Fetching rows in batches reduces the number of calls issued to the database server, and can also reduce network traffic and logical IO overhead. Fetching rows one at a time is like moving thousands of people from one side of a river to another in a boat with all but one of the seats empty - it’s incredibly inefficient.
Fetching rows using the array interface is simple as can be and in fact enabled by default - though with a small default batch size of 10. The setFetchSize method of the connection and statement objects sets the number of rows to be batched. Unfortunately, the default setting of 10 is often far too small – especially since there is typically no degradation even when the fetch size is set very large – you get diminishing, but never negative, returns as you increase the fetch size beyond the point at which every SQL*NET packet is full
Here’s a bit of code that sets the fetch size to 1000 before executing the SQL:
1: val s1 = con.createStatement()
2:
3: s1.setFetchSize(1000)
4: val rs = s1.executeQuery("Select /*fetchsize=" + s1.getFetchSize() + " */ * " +
5: "from customers where rownum<= " + rows)
6: while (rs.next()) {
7: val c1 = rs.getString(1)
8: val c2 = rs.getString(2)
9: }
10: rs.close()
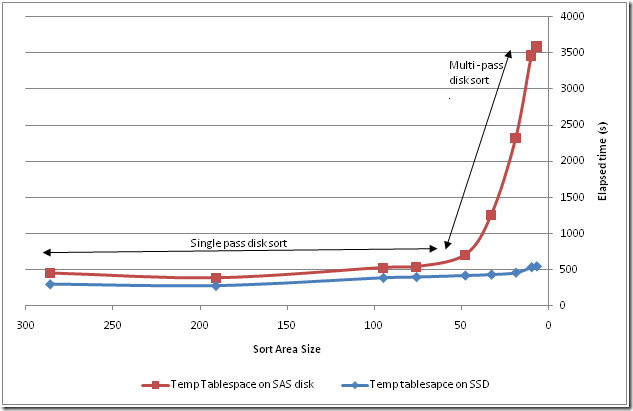
Here’s the elapsed times for various fetchsizes for the above query:

While the default setting of 10 is clearly better than any lower value, it’s still more than 6 times worse than a setting of 100 or 200.
Inserting data is another situation in which we normally want to consider the array interface. In this case we need to change our code structure a bit more noticeably. Here’s the code we probably would write if we didn’t know about array processing:
1: val insSQL = "INSERT into arrayinsertTest" +
2: " (cust_id,cust_first_name,cust_last_name,cust_street_address) " +
3: " VALUES(:1,:2,:3,:4)"
4: val insStmt = con.prepareStatement(insSQL)
5: val startMs = System.currentTimeMillis
6: var rowCount = 0
7: while (rs.next()) {
8: insStmt.setInt(1, rs.getInt(1))
9: insStmt.setString(2, rs.getString(2))
10: insStmt.setString(3, rs.getString(3))
11: insStmt.setString(4, rs.getString(4))
12: rowCount += insStmt.executeUpdate()
13: }
14: val elapsedMs = System.currentTimeMillis - startMs
15: println(rowCount + " rows inserted - " + elapsedMs + " ms")
16: con.commit()
We prepare the statement on line 4, bind the values to be inserted on lines 8-11, then execute the insert on line 12.
WIth a few minor changes, this code can perform array inserts:
1: val insSQL = "INSERT into arrayinsertTest" +
2: " (cust_id,cust_first_name,cust_last_name,cust_street_address) " +
3: " VALUES(:1,:2,:3,:4)"
4: val insStmt = con.prepareStatement(insSQL)
5: val startMs = System.currentTimeMillis
6: var rowCount = 0
7: while (rs.next()) {
8: insStmt.setInt(1, rs.getInt(1))
9: insStmt.setString(2, rs.getString(2))
10: insStmt.setString(3, rs.getString(3))
11: insStmt.setString(4, rs.getString(4))
12: insStmt.addBatch()
13: rowCount += 1
14: if (rowCount % batchSize == 0) {
15: insStmt.executeBatch()
16: }
17: }
18:
19: val elapsedMs = System.currentTimeMillis - startMs
20: println(rowCount + " rows inserted - " + elapsedMs + " ms")
21: con.commit()
On line 12, we now call the addBatch() method instead of executeUpdate(). Once we’ve added enough rows to our batch (defined by the batchsize constant in the above code) we can call executeBatch() to insert the batch.
Array insert gives about the same performance improvements as array fetch. For the above example I got the performance improvement below:

To be fair, the examples above are a best case scenario for array processing – the Oracle database was running in an Amazon EC2 instance in the US, while I was running the scala code from my home in Australia! So the round trip time was as bad as you are ever likely to see. Nevertheless, you see pretty impressive performance enhancements from simply increasing array size in the real world all the time.
Conclusion
If you use JDBC to get data from Oracle RDBMS within a scala project, then the principles for optimization are the same as for Java JDBC – use preparedStatements, bind variables and array processing. Of course there’s a lot more involved in optimizing database queries (SQL Tuning, indexing, etc), but these are the three techniques that vary significantly from language to language. The performance delta from these simple techniques are very significant and should represent the default pattern for a professional database programmer.