Statistical analysis of Oracle performance data using R
R is without doubt the Open Source tool of choice for statistical analysis, it contains a huge variety of statistical analysis techniques – rivalled only by hugely expensive commercial products such as SAS and SPSS. I’ve been playing with R a bit lately, and – of course – working with data held in Oracle. In particular, I’ve been playing with data held in the Oracle dynamic performance views.
This post is a brief overview of installing R, connecting R to Oracle, and using R to analyse Oracle performance data.
Installing R
R can be install in linux as a standard package:
yum install R
On Windows, you may wish to use the Revolution R binaries: http://info.revolutionanalytics.com/download-revolution-r-community.html. I had a bit of trouble installing the 32-bit binaries on my system as they conflicted with my 64-bit JDBC. But if you are 32-bit you might be OK.
The easiest way to setup a connection to Oracle in to install the RJDBC package.
[oracle@GuysOEL ~]$ R
R version 2.12.1 (2010-12-16)
Copyright (C) 2010 The R Foundation for Statistical Computing
ISBN 3-900051-07-0
Platform: x86_64-redhat-linux-gnu (64-bit)
<snip>
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
> install.packages("RJDBC")
Using the StatET Eclipse plug-in
I use a free eclipse plug-in called StatET. It provides an editing environment and GUI console for the R system. The configuration steps are a little laborious, but it has a online getting started module that guides you through the steps. Once you have it installed, I doubt you’ll go back to the command line.

You can get StatET at http://www.walware.de/goto/statet. Using the eclipse environment is really handy if you’re going to use R with Oracle, since you can also use the free Toad for Eclipse extension to work on your SQLs. Eclipse becomes a complete environment for both R and Oracle.
Getting data from Oracle into R
Once you’ve installed R, it’s pretty simple to get data out of Oracle and into R. Here’s a very short snippet that grabs data from the V$SQL table:
1: library(RJDBC)
2:
3: drv <- JDBC("oracle.jdbc.driver.OracleDriver",
4: "/ora11/home/jdbc/lib/ojdbc6.jar")
5:
6: conn <- dbConnect(drv,"jdbc:oracle:thin:@hostname:1521: service","username","password")
7: sqldata<-dbGetQuery(conn, "SELECT cpu_time cpu,elapsed_time ela,disk_reads phys,
8: buffer_gets bg,sorts sorts
9: FROM V$SQL ")
10: summary(sqldata)
Let’s look at that line by line:
| Line | Comments |
| 1 | The library command loads the RJDBC module, which will provide connectivity to Oracle. |
| 3 | We create a driver object for the Oracle JDBC driver. The second argument is the location of the Oracle JDBC jar file, almost always $ORACLE_HOME/jdbc/lib/ojdbc6.jar. |
| 6 | Connect to the Oracle database using standard JDBC connections strings |
| 7 | Create an R dataset from the result set of a query. In this case, we are loading the contents of the V$SQL table. |
| 10 | The R “summary” package provides simple descriptive statistics for each variable in the provided dataset. |
Basic R statistical functions
R has hundreds of statistical functions, in the above example we used “summary”, which prints descriptive statistics. The output is shown below; mean, medians, percentiles, etc:

Correlation
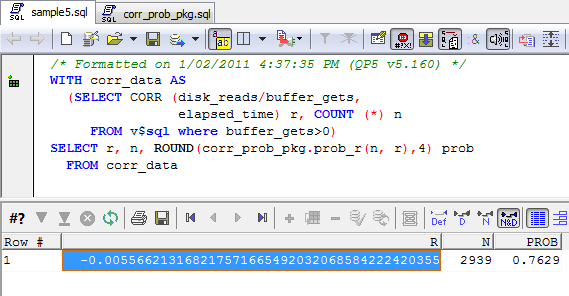
Statistical correlation reveals the association between two numeric variables. If two variables always increase or decrease together the correlation is 1; if two variables are absolutely random with respect of each other then the correlation tends towards 0.
cor prints the correlation between every variable in the data set:

cor.test calculates the correlation coefficient and prints out the statistical significance of the correlation, which allows you to determine if there is a significant relationship between the two variables. So does the number of sorts affect response time? Let’s find out:

The p-value is 0.19 which indicates no significant relationship – p values of no more than 0.05 (one chance in 20) are usually requires before we assume statistical significance.
On the other hand, there is a strong relationship between CPU time and Elapsed time:

Plotting
plot prints a scattergram chart. Here’s the output from plot(sqldata$ELA,sqldata$CPU):

Here’s a slightly more sophisticated chart using “smoothScatter”, logarithmic axes and labels for the axes:

Regression
Regression is used to draw “lines of best fit” between variables.
In the simplest case, we use the “lm” package to create a linear regression model between two variables (which we call “regdata” in the example). The summary function prints a summary of the analysis:

This might seem a little mysterious if your statistics is a bit rusty, but the data above tells us that there is a significant relationship between elapsed time (ELA) and physical reads (PHYS) and gives us the gradient and Y axis intercept if we wanted to draw the relationship. We can get R to draw a graph, and plot the original data by using the plot at abline functions:

Testing a hypothesis
One of the benefits of statistical analysis is you can test hypotheses about your data. For instance, what about we test the until recently widely held notion that the buffer cache hit rate is a good measure of performance. We might suppose if that were true that SQL statements with high buffer cache hit rates would show smaller elapsed times than those with low buffer cache hit rates. To be sure, there are certain hidden assumptions underlying that hypothesis, but for the sake of illustration let’s use R to see if our data supports the hypothesis.
Simple correlation is a fair test for this, all we need to do is see if there is a statistically signifcant correlation between hit rate and elapsed time. Here’s the analysis:

The correlation is close to 0, and the statistical significance way higher than the widely accepted .05 threshold for statistical significance. Statements with high hit ratios do not show statistically signficantly lower elasped times that SQLs with low hit ratios.
Conclusion
There’s tons of data in our Oracle databases that could benefit from statistical analysis – not the least the performance data in the dynamic performance views, ASH and AWR. We use statistical tests in Spotlight on Oracle to extrapolate performance into the future and to set some of the alarm thresholds. Using R, you have easy access to the most sophisticated statistical analysis techniques and as I hope I’ve shown, you can easily integrate R with Oracle data.